TLT:把 reasoning RL 的长尾 rollout,变成可利用的系统机会
先讲 RL / SD 是什么,再讲 SD 什么情况下赚、什么时候会亏,最后讲 TLT 具体怎么设计。
关键信息
- 问题:rollout 是整轮 RL step 的大头
- 工具:speculative decoding
- 难点:(动态性)target 持续变化 + batch 动态缩小
- 方案:Adaptive Rollout Engine + Adaptive Drafter
一句话版本
对于复杂依赖问题,通常有两种解决办法:第一种是真的把执行时间降下来,比如本文用 SD 直接缩短长尾 rollout;第二种是把资源利用里的 bubble 填上,比如本文用长尾阶段空出来的 GPU 去训练和维护 drafter。
关键数字
1.7-2.1x:相对 VeRL 的端到端训练加速。rollout ≈ 85%:论文强调 rollout 是单步时间大头。2.8x:CUDA Graph 缓存开销减小量9.2x:checkpoint 的显存占用减少量 这里只指 checkpoint 相关缓存/保存占用,不是总显存。
1. RL 和 SD 是什么
先不谈 TLT。先把 reasoning RL 这一轮到底怎么跑,以及 SD 到底在省什么,讲清楚。
先做,再按结果好坏调
标签:RL 是什么
监督学习像“告诉模型标准答案”;RL 更像“先让模型自己做,再根据最终结果好不好来调整它”。对数学、代码、复杂推理,这种方式更现实。
结果可验,过程难标
标签:为什么用在推理
数学题能看最终答案,代码题能跑测试,但中间 reasoning trace 很难逐 token 标注。RL 就适合这类“最终可判、过程难监督”的任务。
reasoning RL
标签:本文场景
这篇论文关注的是让模型更会推理,而不是普通聊天调优。典型表现就是 response 更长、rollout 更贵、长尾更明显。
一轮 RL step 是怎么跑的

更准确地说,这里同时有两层串行性:token 级自回归依赖 和 step 级完整 response 屏障。前者让单条长回答本身很慢,后者又让整轮训练必须等它结束。
Rollout
标签:术语 1
模型真的开始答题,生成完整 response。本文里这是最慢的阶段。
Reward
标签:术语 2
对 response 打分。数学题看答案,代码题跑测试,格式错误也可能扣分。
Reference Model(冻结旧模型)
标签:术语 3
可以把它理解成“安全绳”。target 每次 RL 更新后,都拿它和这个旧模型比一下:如果 target 在某些 token 上突然和旧模型差太远,就加一个 KL 惩罚,把它往回拽一点,避免模型为了追 reward 一下子学歪。
Update
标签:术语 4
把高分回答概率拉高,把低分回答概率拉低,然后进入下一轮。
SD 在做什么

SD 的关键不是“小模型替代大模型”,而是:把原来很多次串行 decode step,压成一次更并行的验证步。
target 为什么能一次检查多个位置

把
d1 d2 d3喂进去,不等于承认它们正确;只是让 target 对这些位置逐个打分。如果d1没通过,那么检查d2用到的前缀A B C d1就失效了,所以后面的结果要一起丢弃。
2. SD 什么时候有优势,什么时候会吃亏
SD 不是永远有收益。它的收益取决于 batch 大小、response 长度、drafter 质量,以及当前是不是已经进入长尾后半段。
小 batch、长 response、drafter 准
标签:更容易赚钱
活跃请求少、response 还很长、accept length 高时,普通 decode 吃不满 GPU,而 SD 更容易一次推进多个 token。
大 batch、短序列、drafter 过时
标签:更容易亏
这时 drafter 额外开销可能盖过收益。如果猜测经常被拒,target 平均每轮还是只能前进 1 个 token,SD 就不值。
一轮 rollout 的形状
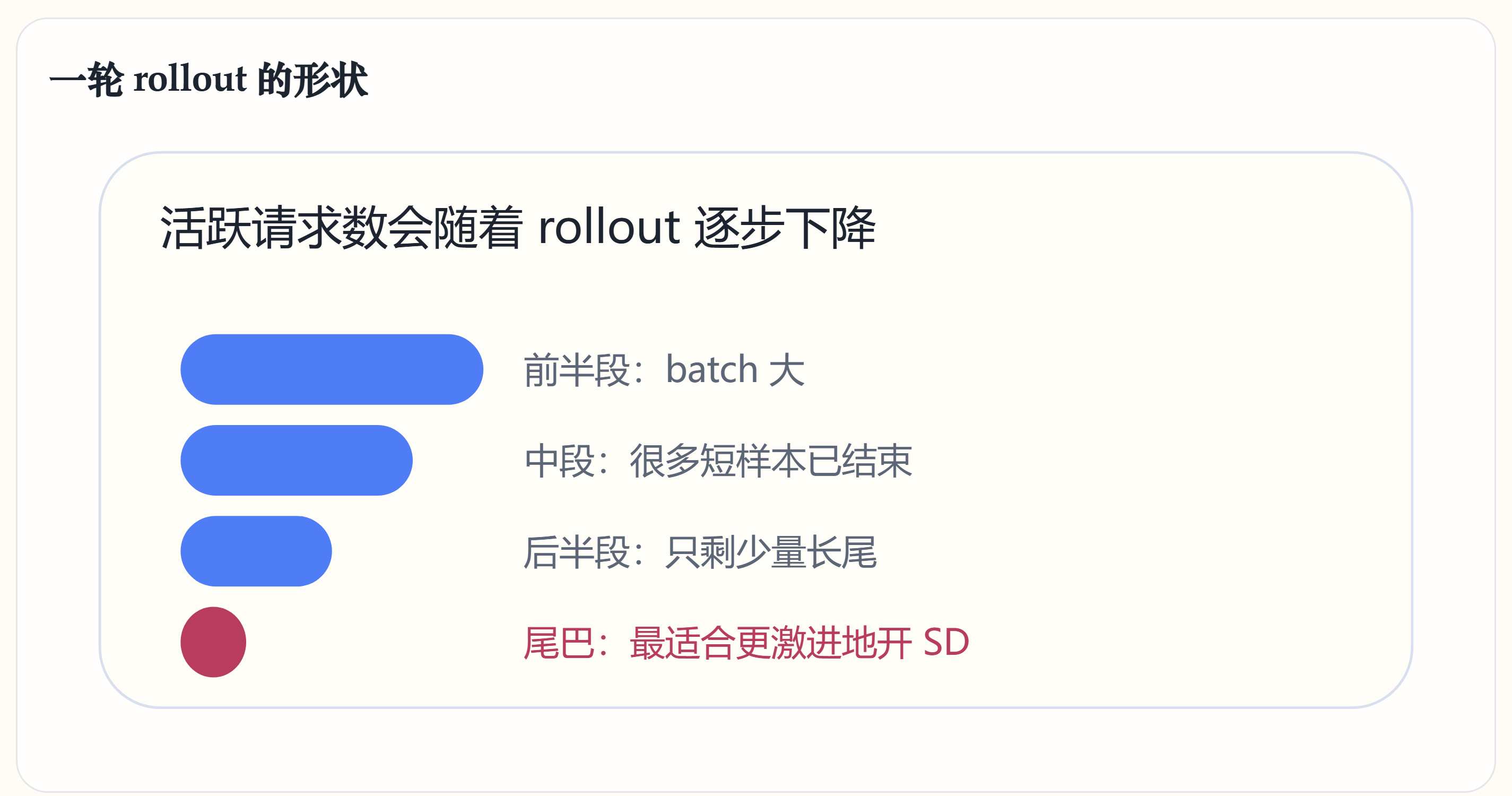
论文怎么避免“SD 在错误时机反而拖慢”
Elastic enable
标签:策略 1
请求还很多时先不开,等活跃请求数降到阈值以下再开。
动态选参
标签:策略 2
不同 batch size 用不同的 draft depth、verify token 数,不是一套参数跑到底。
维持 drafter 质量
标签:策略 3
target 在持续变化,drafter 不更新就会 stale,accept length 会掉。
3. 本文的设计:TLT 具体做了什么
理解了 RL 流程和 SD 的适用条件之后,再看 TLT 就会更顺:它不是“开 SD”这么简单,而是把两条系统思路拼起来了。上层直接缩短长尾 rollout 的关键路径,下层把长尾阶段释放出来的 bubble 拿去维护 drafter。
长尾 rollout
标签:难点 1
大量短回答先结束,少量长回答继续拖时间,后面的打分、和旧模型比较、loss/update 还得等它们。
drafter 会过时
标签:难点 2
target 每一轮都在更新。静态 drafter 很快会和当前 target 脱节,accept length 下降。
最优 SD 配置一直在变
标签:难点 3
活跃请求数不断缩小,最合适的 verify token 数和 draft depth 也在变化。
TLT 总体结构
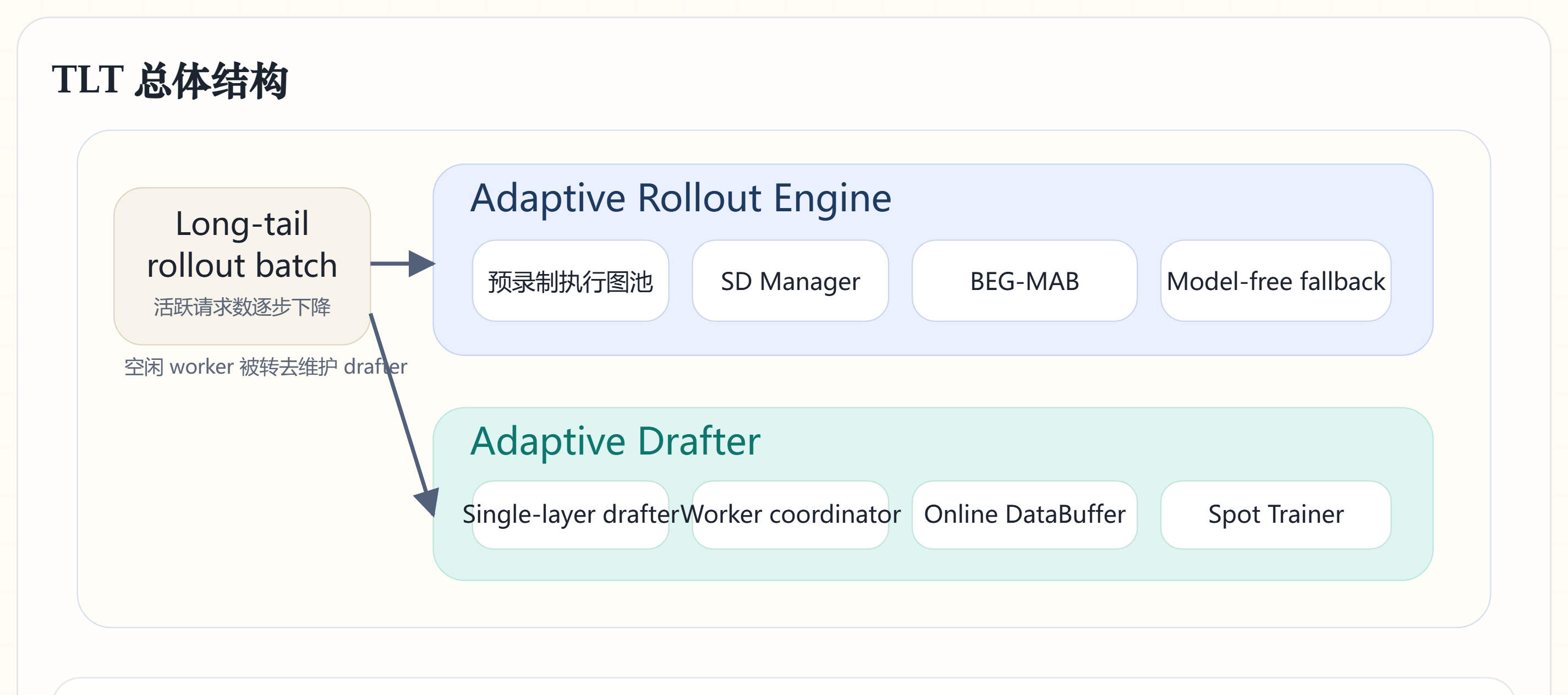
一句话:上半部分是在减当前长尾 rollout 的执行时间,下半部分是在把长尾旁边已经出现的 bubble 填满,并顺手维持 drafter 质量。
Design A:Adaptive Rollout Engine
这两块都偏工程实现:BEG-MAB 负责轻量级在线选参,Bucketed CUDAGraph 负责把这些候选策略预先录好且别占太多图缓存。运行时主要是“看当前 batch 落在哪个桶里,然后取对应图 replay”,不是临时重新录图。
Elastic enable
标签:A1
不是从头到尾都开 SD,而是等请求数下降后再启用。
BEG-MAB
标签:A2
先按当前 batch size 落到一个桶里,只在这个桶允许的几种 SD 配置里选。它不给每步都跑重搜索,只维护每个候选最近一小段窗口的收益统计;收益大致就是“每单位时间实际推进了多少 accepted tokens”。大多数时候选最近中位数收益最好的,少数时候随机试一下,所以在线开销很轻。
按区间复用执行图
标签:A3
CUDA Graph 缓存开销减小量 本质就是分桶。不是给 batch=17、18、19 各录一份图,而是让一个 batch 区间共用一组图;同时 target 图和 drafter 图拆开录,能共用的策略再合并。这样省下来的主要是图缓存本身占的显存,不是模型参数或 KV cache。
Design B:Adaptive Drafter
单层 drafter
标签:B1
只训练很小的一层,便于频繁更新,也便于推理加速。
Spot training
标签:B2
把长尾释放出来的空闲 worker 拿来做drafter训练,不阻塞主流程。
DataBuffer
标签:B3
rollout / inference 时,target 本来就会算出一串 hidden states 和对应 token。TLT 把这些中间结果顺手存到 host memory 里的 DataBuffer;之后 spot training 直接读取这些现成特征来训 drafter,不必再为同一批样本重跑一遍 target prefill。这个 buffer 还会跨 RL step 保留,优先补一些上一轮留下来的长序列,缓解“当前已完成样本大多偏短”的偏置。
很关键的边界:空出来的 GPU 主要不是直接去“帮当前长尾 token 并行算”,而是去维护 drafter;当前尾巴真正的直接加速来源,仍然是已经启用的 SD。spot training 更稳妥的作用,是让后续 RL steps 的 SD 持续有效。